import tkinter as tk
from tkinter import messagebox
import urllib.request
import requests
import re
import sys
def inquire():
cityName = entry.get() # 获取输入框信息
if cityName == ‘‘:
messagebox.showinfo(‘提示‘, ‘请输入您要查询的城市!‘)
else:
city = urllib.request.quote(cityName) # urllib.request.quote()将汉字编码
raw_url = ‘https://www.tianqi.com/?keyword=‘ + city
header = {‘user-agent‘:‘Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.16 Safari/537.36‘}
resp = requests.get(raw_url, headers = header)
reg = re.compile(‘<li><a href="(.*?)" title="%s天气预报">%s天气预报</a></li>‘ % (cityName, cityName))
try:
url = re.findall(reg, resp.text)[0] # 获得要查询城市天气预报的网址url
resp = requests.get(url, headers = header)
except:
messagebox.showinfo(‘警告‘, ‘您输入的城市查不到!‘)
sys.exit()
reg = re.compile(‘<dd class="week">(.*?)</dd>‘)
cur_date = re.findall(reg,resp.text)[0] # 提取当前日期
reg = re.compile(‘<p class="now"><b>(.*?)</b><i>℃</i></p>‘)
cur_temperature = re.findall(reg, resp.text)[0] # 提取当前温度
reg = re.compile(‘<span><b>(.*?)</b>(.*?)</span>‘)
cur_weather, cur_trange = re.findall(reg, resp.text)[0][0],re.findall(reg, resp.text)[0][1] #提取当前天气,温度范围
# 在listbox列表框中显示天气
lis.delete(0, tk.END) # 首先清空列表框
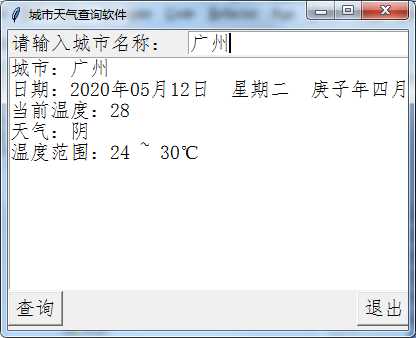
lis.insert(0, ‘城市:%s‘ % cityName)
lis.insert(1, ‘日期:%s‘ % cur_date)
lis.insert(2, ‘当前温度:%s‘ % cur_temperature)
lis.insert(3, ‘天气:%s‘ % cur_weather)
lis.insert(4, ‘温度范围:%s‘ % cur_trange)
root = tk.Tk()
root.title(‘城市天气查询软件‘)
root.geometry(‘400x300+20+20‘)
label = tk.Label(root, text = ‘请输入城市名称:‘,font = (‘仿宋‘, 15))
label.grid(row = 0, column = 0, sticky = tk.W)
entry = tk.Entry(root, font = (‘仿宋‘, 15),width = 22)
entry.grid(row = 0, column = 1, sticky = tk.E)
lis = tk.Listbox(root, font = (‘仿宋‘, 15),width = 40, height = 11)
lis.grid(row = 1, columnspan = 2, sticky = tk.W)
btn1 = tk.Button(root, text = ‘查询‘, font = (‘仿宋‘, 15), command = inquire)
btn1.grid(row = 2, column = 0, sticky = tk.W)
btn2 = tk.Button(root, text = ‘退出‘, font = (‘仿宋‘, 15), command = root.quit)
btn2.grid(row = 2, column = 1, sticky = tk.E)
root.mainloop()
运行后效果: