微信公众号里放XLS链接的教程
我们都知道创建一个微信公众号,在公众号中发布一些文章是非常简单的,但公众号添加附件下载的功能却被限制,如今可以使用小程序“微附件”进行在公众号中添加附件,如:xls,word等。
以下是公众号添加附件使用“微附件”小程序的教程:
电脑端使用“微附件”:
大体上分为两步:
第一步:将附件上传到“微附件”小程序,或官方网站,这里只演示上传到官网的。
第二步:在微信公众号后台操作就可以了。
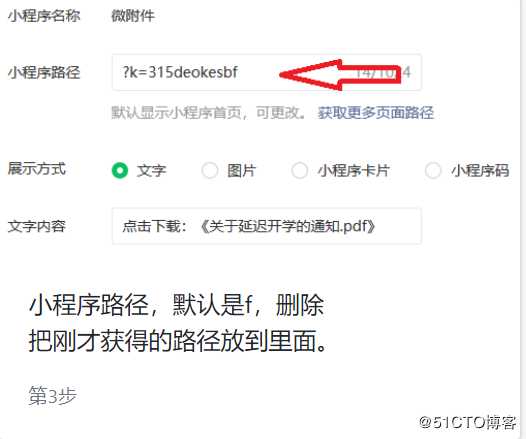
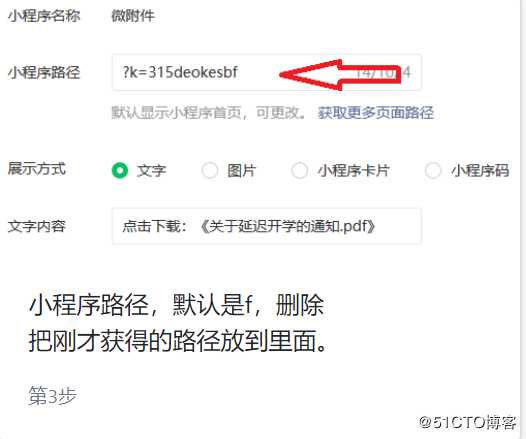
1、进入官方网站,上传附件,注意一下路径,后面要用。
2、已关联过小程序的按照下面步骤操作即可。未关联过小程序的公众号,要点击“小程序”,再点击“开通”,扫描二维码,搜索“微附件”关联即可。
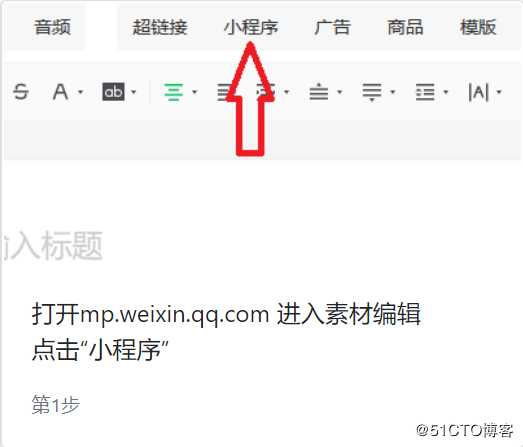
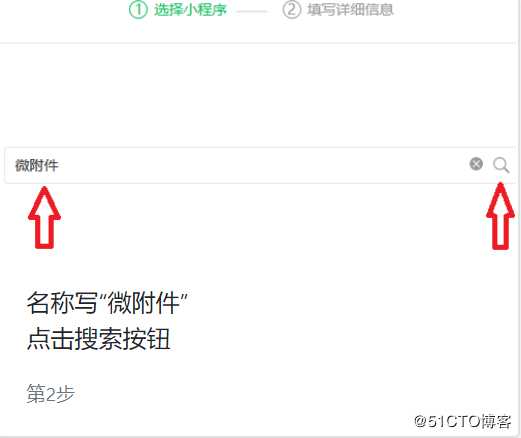
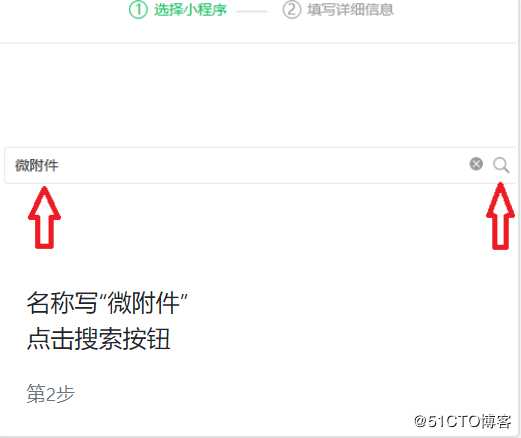
3、进入微信公众号后台素材编辑区,点击“小程序”,并搜索“微附件”,点击“下一步”。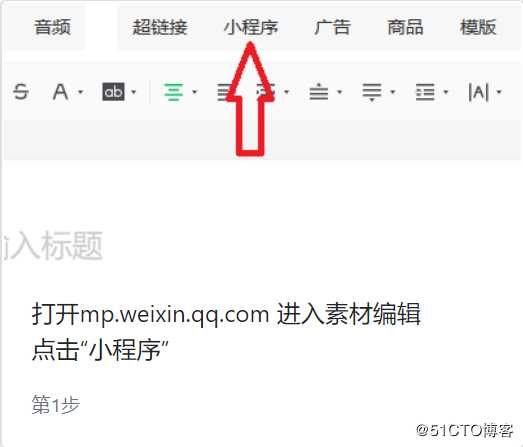
通过“微附件”小程序可以实现,公众号文章下载附件,自定义菜单下载附件,自动回复下载附件等功能。
手机端使用“微附件”:
微信公众号文章页添加附件的教程
大体上分为两步:
第一步:将附件上传到“微附件”小程序,或官方网站:https://fujian.uom.cn/。
第二步:在微信公众号后台操作就可以了。
1、搜索微信小程序:微附件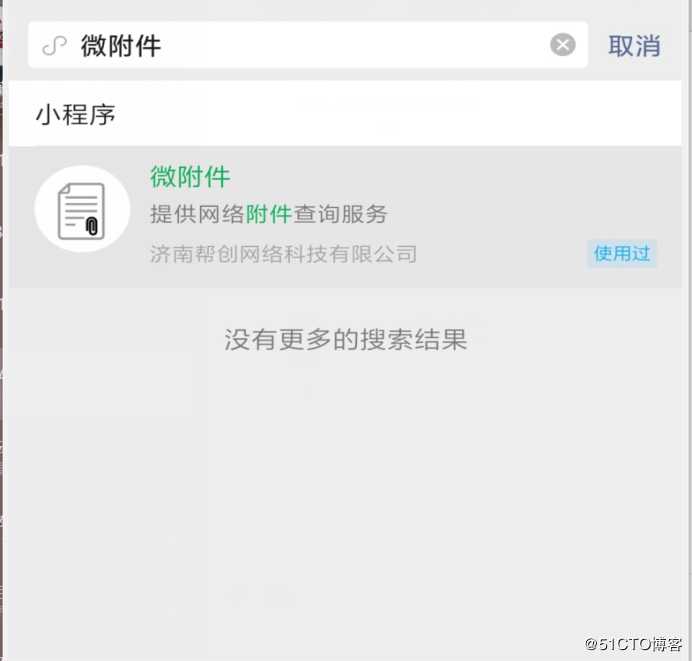
2、点击进入微附件小程序,点击“上传”按钮,上传需要发在公众号的文档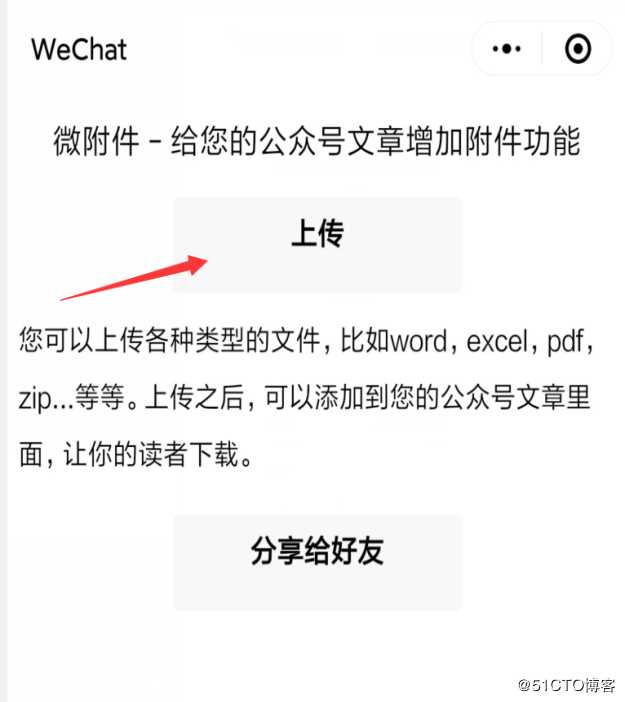
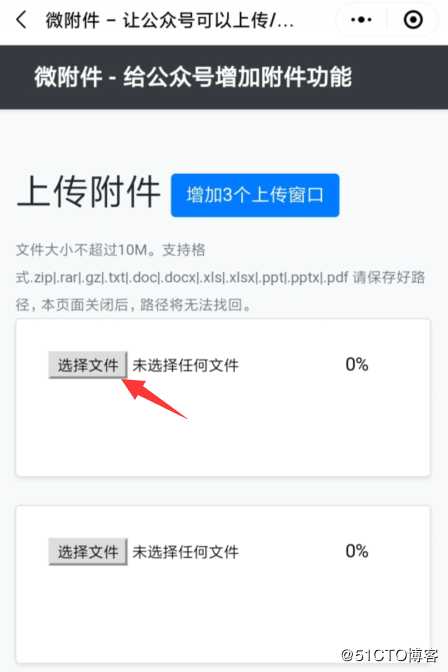
3、上传成功后,记下路径。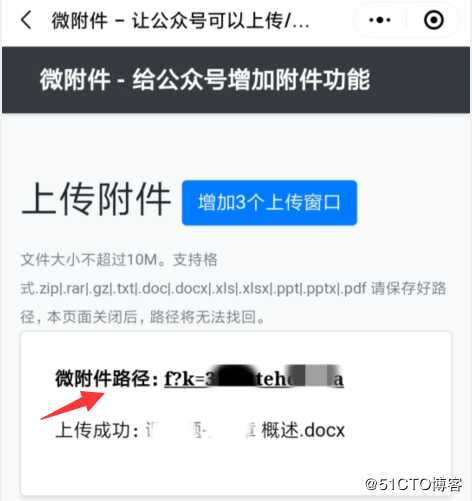
4、进入微信公众号后台素材编辑区,点击“小程序”,并搜索“微附件”,点击“下一步”。