上一章介绍了经过路由的处理,一个请求找到了具体处理这个请求的EndPoint,并最终执行它的RequestDelegate方法来处理这个Httpcontext。本章继续这个处理进程,按照惯例,依然通过几幅图来聊一聊这个RequestDelegate之后的故事。在此就避免不了的聊到各种Filter,它方便我们在action执行的前后做一些 “小动作”。(ASP.NET Core 系列目录)
一、概述
首先看一下RequestDelegate这个方法:
RequestDelegate requestDelegate = (context) => { var routeData = context.GetRouteData(); var actionContext = new ActionContext(context, routeData, action); var invoker = _invokerFactory.CreateInvoker(actionContext); return invoker.InvokeAsync(); };
将这个方法的内容分为两部分:
A. invoker的生成,前三句,通过CreateInvoker方法生成了一个invoker,它是一个比较复杂的综合体,包含了controller的创建工厂、参数的绑定方法以及本action相关的各种Filter的集合等, 也就是说它是前期准备工作阶段,这个阶段扩展开来涉及面比较广,在下文详细描述。
B.invoker的执行,最后一句,前面已经万事俱备,准备了好多方法,到此来执行。此时涉及到前面准备的各种方法的执行,各种Filter也在此时被执行。
二、invoker的生成
依照习惯,还是通过流程图来看一看:
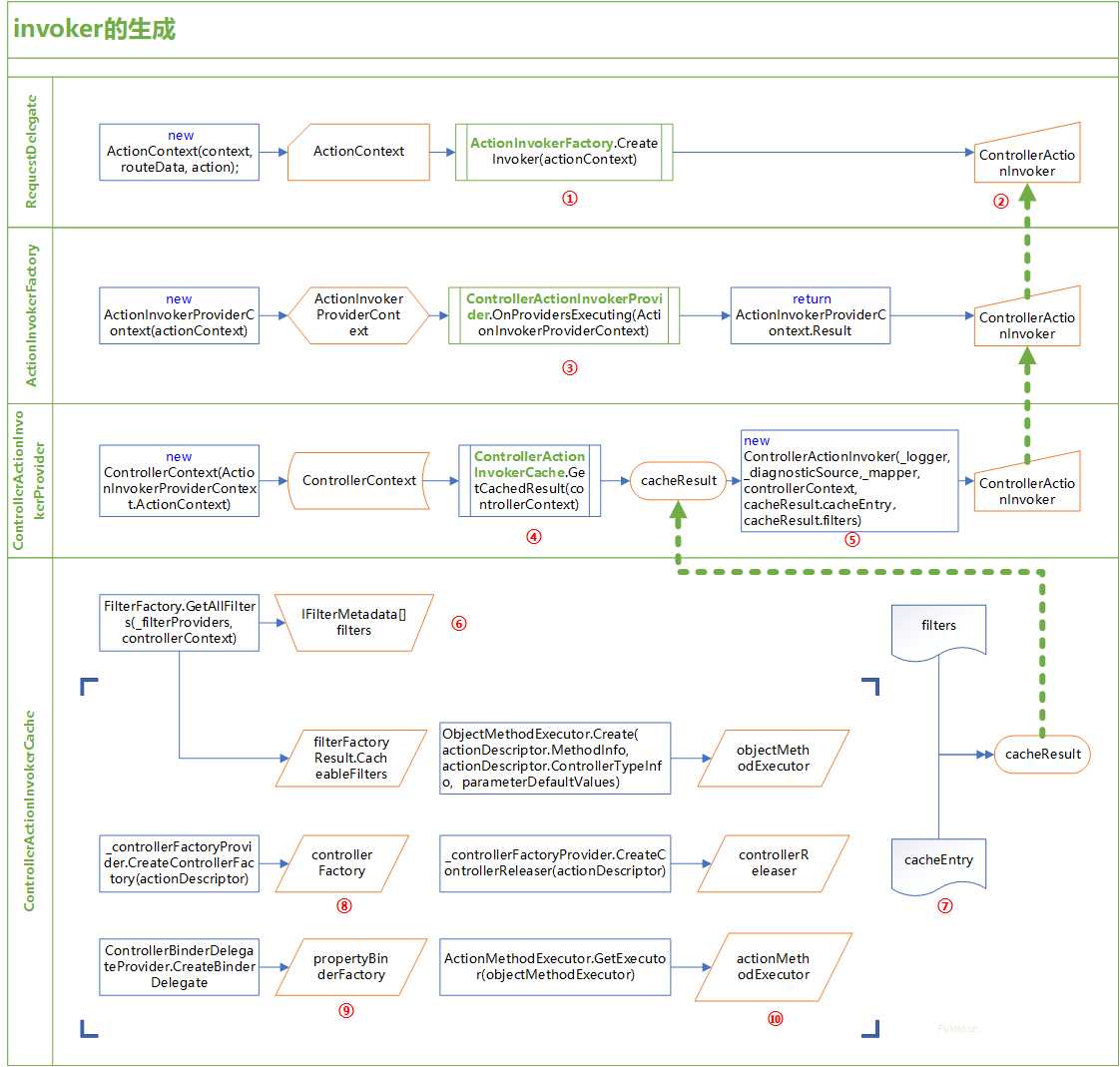
图一(点击查看大图)
首先说一下此图的结构,每个泳道相当于是上一个泳道中的 图标的细化说明,例如第二条泳道是图标①标识的方块的明细化。
图标的细化说明,例如第二条泳道是图标①标识的方块的明细化。
A. 泳道一:
就是第一节【概述】中描述的的内容,不再赘述。另外提一下本文的核心invoker本质上就是一个ControllerActionInvoker,也是图中的ActionInvokerProviderContext.Result。
B.泳道二:即①的详细描述
① ActionInvokerFactory.CreateInvoker(actionContext)
1 public IActionInvoker CreateInvoker(ActionContext actionContext) 2 { 3 var context = new ActionInvokerProviderContext(actionContext); 4 5 foreach (var provider in _actionInvokerProviders) 6 { 7 provider.OnProvidersExecuting(context); 8 } 9 10 for (var i = _actionInvokerProviders.Length - 1; i >= 0; i--) 11 { 12 _actionInvokerProviders[i].OnProvidersExecuted(context); 13 } 14 15 return context.Result; 16 }
本章设计的这部分内容比较常见的一个操作就是context的封装,这从第一个泳道的第一个操作就开始了, 他将HttpContext、RouteData,ActionDescriptor封装到一起成了一个ActionContext ,而到了这个方法,又将这个ActionContext 封装成了ActionInvokerProviderContext,接下来就是遍历_actionInvokerProviders调用它们的OnProvidersExecuting和OnProvidersExecuted方法来设置ActionInvokerProviderContext.Result,也就是最终的ControllerActionInvoker。
这里说一下_actionInvokerProviders,它的类型是IActionInvokerProvider[],默认情况下包含了两个,分别是ControllerActionInvokerProvider和PageActionInvokerProvider,第一个是用于MVC的action的处理,而第二个用于Razor Pages Web的处理。二者的OnProvidersExecuting方法都会首先判断当前action是不是自己对应的类型,若不是则直接跳过。二者的OnProvidersExecuted方法目前均为空。所以图中和下面关于OnProvidersExecuting的描述也仅限于ControllerActionInvokerProvider的OnProvidersExecuting方法。
C.泳道三:ControllerActionInvokerProvider.OnProvidersExecuting(context)
即泳道二中的③的详细描述
1 public void OnProvidersExecuting(ActionInvokerProviderContext context) 2 { 3 if (context.ActionContext.ActionDescriptor is ControllerActionDescriptor) 4 { 5 var controllerContext = new ControllerContext(context.ActionContext); 6 // PERF: These are rarely going to be changed, so let‘s go copy-on-write. 7 controllerContext.ValueProviderFactories = new CopyOnWriteList<IValueProviderFactory>(_valueProviderFactories); 8 controllerContext.ModelState.MaxAllowedErrors = _maxModelValidationErrors; 9 10 var cacheResult = _controllerActionInvokerCache.GetCachedResult(controllerContext); 11 12 var invoker = new ControllerActionInvoker( 13 _logger, 14 _diagnosticSource, 15 _mapper, 16 controllerContext, 17 cacheResult.cacheEntry, 18 cacheResult.filters); 19 20 context.Result = invoker; 21 } 22 }
如上文所述,在处理之前,首先就是判断当前action是否是自己对应处理的类型。然后就是继续封装大法,将ActionContext封装成了ControllerContext。进而是调用GetCachedResult方法读取两个关键内容cacheResult.cacheEntry和cacheResult.filters后,将其封装成ControllerActionInvoker(⑤)。
D.第四条泳道:
对应的是第三条中的④ControllerActionInvokerCache.GetCachedResult(controllerContext);
1 public (ControllerActionInvokerCacheEntry cacheEntry, IFilterMetadata[] filters) GetCachedResult(ControllerContext controllerContext) 2 { 3 var cache = CurrentCache; 4 var actionDescriptor = controllerContext.ActionDescriptor; 5 6 IFilterMetadata[] filters; 7 if (!cache.Entries.TryGetValue(actionDescriptor, out var cacheEntry)) 8 { 9 var filterFactoryResult = FilterFactory.GetAllFilters(_filterProviders, controllerContext); 10 filters = filterFactoryResult.Filters; 11 12 var parameterDefaultValues = ParameterDefaultValues 13 .GetParameterDefaultValues(actionDescriptor.MethodInfo); 14 15 var objectMethodExecutor = ObjectMethodExecutor.Create( 16 actionDescriptor.MethodInfo, 17 actionDescriptor.ControllerTypeInfo, 18 parameterDefaultValues); 19 20 var controllerFactory = _controllerFactoryProvider.CreateControllerFactory(actionDescriptor); 21 var controllerReleaser = _controllerFactoryProvider.CreateControllerReleaser(actionDescriptor); 22 var propertyBinderFactory = ControllerBinderDelegateProvider.CreateBinderDelegate( 23 _parameterBinder, 24 _modelBinderFactory, 25 _modelMetadataProvider, 26 actionDescriptor, 27 _mvcOptions); 28 29 var actionMethodExecutor = ActionMethodExecutor.GetExecutor(objectMethodExecutor); 30 31 cacheEntry = new ControllerActionInvokerCacheEntry( 32 filterFactoryResult.CacheableFilters, 33 controllerFactory, 34 controllerReleaser, 35 propertyBinderFactory, 36 objectMethodExecutor, 37 actionMethodExecutor); 38 cacheEntry = cache.Entries.GetOrAdd(actionDescriptor, cacheEntry); 39 } 40 else 41 { 42 // Filter instances from statically defined filter descriptors + from filter providers 43 filters = FilterFactory.CreateUncachedFilters(_filterProviders, controllerContext, cacheEntry.CachedFilters); 44 } 45 46 return (cacheEntry, filters);
总的来看,本段内容主要是为了组装cacheEntry和 filters两个内容,而一个大的 if 体现出这里加入了缓存机制,使系统不必每次都去拼凑这些,提高执行效率。
⑥IFilterMetadata[] filters,它是一个filter的集和,首先调用FilterFactory的GetAllFilters(_filterProviders, controllerContext)方法获取当前action对应的所有Filter并对这些Filter进行排序(Filter部分将在之后章节分享)。
接下来就是组装⑦cacheEntry,它的内容比较多,比较重要的几个有:⑧ controllerFactory和controllerReleaser他们的本质都是Func<ControllerContext, object>,也就是Controller的Create和Release方法。 ⑨propertyBinderFactory 是一个用于参数绑定的Task,可以说也是一个组装好准备被执行的方法。最后一个⑩actionMethodExecutor也就是执行者,通过ActionMethodExecutor.GetExecutor(objectMethodExecutor)方法从众多的action执行者(如图二)中找出一个当前action对应的执行者出来。

图二
总结: 本节invoker的生成,总的来说就是一个执行前“万事俱备”的过程,invoker是一个组装起来的集合,它包含一个人(执行者actionMethodExecutor)、N把枪(组装好用于“被执行”的方法例如controllerFactory、controllerReleaser和propertyBinderFactory,当然还有个filter的集和)。由此也可以进一步想到,接下来的过程就是这些准备好的内容按照一定的顺序逐步执行的过程。
二、invoker的执行
invoker的执行也就是invoker.InvokeAsync(),虽然invoker本质上是ControllerActionInvoker,但这个方法写在ResourceInvoker类中, ControllerActionInvoker : ResourceInvoker, IActionInvoker 。
public virtual async Task InvokeAsync() { try { await InvokeFilterPipelineAsync(); } finally { ReleaseResources(); _logger.ExecutedAction(_actionContext.ActionDescriptor, stopwatch.GetElapsedTime()); } } private async Task InvokeFilterPipelineAsync() { var next = State.InvokeBegin; var scope = Scope.Invoker; var state = (object)null; // `isCompleted` will be set to true when we‘ve reached a terminal state. var isCompleted = false; while (!isCompleted) { await Next(ref next, ref scope, ref state, ref isCompleted); } }
看似比较简单的两个方法,从InvokeAsync方法中可以看出来,请求会进入筛选器管道进行处理,也就是 Task InvokeFilterPipelineAsync() 方法,借用官方文档中的一个图看一下
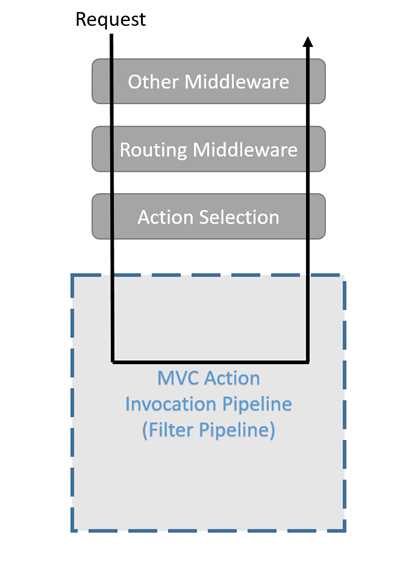
图三
此图描述了请求经过其他中间件处理后,进入路由处理最终找到了对应的action,最终进入筛选器管道进行处理。而这个处理的核心部分就是方法中的 while (!isCompleted) 循环,它对应的Next方法比较长,如下(较长已折叠)


1 private Task Next(ref State next, ref Scope scope, ref object state, ref bool isCompleted) 2 { 3 switch (next) 4 { 5 case State.InvokeBegin: 6 { 7 goto case State.AuthorizationBegin; 8 } 9 10 case State.AuthorizationBegin: 11 { 12 _cursor.Reset(); 13 goto case State.AuthorizationNext; 14 } 15 16 case State.AuthorizationNext: 17 { 18 var current = _cursor.GetNextFilter<IAuthorizationFilter, IAsyncAuthorizationFilter>(); 19 if (current.FilterAsync != null) 20 { 21 if (_authorizationContext == null) 22 { 23 _authorizationContext = new AuthorizationFilterContext(_actionContext, _filters); 24 } 25 26 state = current.FilterAsync; 27 goto case State.AuthorizationAsyncBegin; 28 } 29 else if (current.Filter != null) 30 { 31 if (_authorizationContext == null) 32 { 33 _authorizationContext = new AuthorizationFilterContext(_actionContext, _filters); 34 } 35 36 state = current.Filter; 37 goto case State.AuthorizationSync; 38 } 39 else 40 { 41 goto case State.AuthorizationEnd; 42 } 43 } 44 45 case State.AuthorizationAsyncBegin: 46 { 47 Debug.Assert(state != null); 48 Debug.Assert(_authorizationContext != null); 49 50 var filter = (IAsyncAuthorizationFilter)state; 51 var authorizationContext = _authorizationContext; 52 53 _diagnosticSource.BeforeOnAuthorizationAsync(authorizationContext, filter); 54 _logger.BeforeExecutingMethodOnFilter( 55 FilterTypeConstants.AuthorizationFilter, 56 nameof(IAsyncAuthorizationFilter.OnAuthorizationAsync), 57 filter); 58 59 var task = filter.OnAuthorizationAsync(authorizationContext); 60 if (task.Status != TaskStatus.RanToCompletion) 61 { 62 next = State.AuthorizationAsyncEnd; 63 return task; 64 } 65 66 goto case State.AuthorizationAsyncEnd; 67 } 68 69 case State.AuthorizationAsyncEnd: 70 { 71 Debug.Assert(state != null); 72 Debug.Assert(_authorizationContext != null); 73 74 var filter = (IAsyncAuthorizationFilter)state; 75 var authorizationContext = _authorizationContext; 76 77 _diagnosticSource.AfterOnAuthorizationAsync(authorizationContext, filter); 78 _logger.AfterExecutingMethodOnFilter( 79 FilterTypeConstants.AuthorizationFilter, 80 nameof(IAsyncAuthorizationFilter.OnAuthorizationAsync), 81 filter); 82 83 if (authorizationContext.Result != null) 84 { 85 goto case State.AuthorizationShortCircuit; 86 } 87 88 goto case State.AuthorizationNext; 89 } 90 91 case State.AuthorizationSync: 92 { 93 Debug.Assert(state != null); 94 Debug.Assert(_authorizationContext != null); 95 96 var filter = (IAuthorizationFilter)state; 97 var authorizationContext = _authorizationContext; 98 99 _diagnosticSource.BeforeOnAuthorization(authorizationContext, filter); 100 _logger.BeforeExecutingMethodOnFilter( 101 FilterTypeConstants.AuthorizationFilter, 102 nameof(IAuthorizationFilter.OnAuthorization), 103 filter); 104 105 filter.OnAuthorization(authorizationContext); 106 107 _diagnosticSource.AfterOnAuthorization(authorizationContext, filter); 108 _logger.AfterExecutingMethodOnFilter( 109 FilterTypeConstants.AuthorizationFilter, 110 nameof(IAuthorizationFilter.OnAuthorization), 111 filter); 112 113 if (authorizationContext.Result != null) 114 { 115 goto case State.AuthorizationShortCircuit; 116 } 117 118 goto case State.AuthorizationNext; 119 } 120 121 case State.AuthorizationShortCircuit: 122 { 123 Debug.Assert(state != null); 124 Debug.Assert(_authorizationContext != null); 125 Debug.Assert(_authorizationContext.Result != null); 126 127 _logger.AuthorizationFailure((IFilterMetadata)state); 128 129 // This is a short-circuit - execute relevant result filters + result and complete this invocation. 130 isCompleted = true; 131 _result = _authorizationContext.Result; 132 return InvokeAlwaysRunResultFilters(); 133 } 134 135 case State.AuthorizationEnd: 136 { 137 goto case State.ResourceBegin; 138 } 139 140 case State.ResourceBegin: 141 { 142 _cursor.Reset(); 143 goto case State.ResourceNext; 144 } 145 146 case State.ResourceNext: 147 { 148 var current = _cursor.GetNextFilter<IResourceFilter, IAsyncResourceFilter>(); 149 if (current.FilterAsync != null) 150 { 151 if (_resourceExecutingContext == null) 152 { 153 _resourceExecutingContext = new ResourceExecutingContext( 154 _actionContext, 155 _filters, 156 _valueProviderFactories); 157 } 158 159 state = current.FilterAsync; 160 goto case State.ResourceAsyncBegin; 161 } 162 else if (current.Filter != null) 163 { 164 if (_resourceExecutingContext == null) 165 { 166 _resourceExecutingContext = new ResourceExecutingContext( 167 _actionContext, 168 _filters, 169 _valueProviderFactories); 170 } 171 172 state = current.Filter; 173 goto case State.ResourceSyncBegin; 174 } 175 else 176 { 177 // All resource filters are currently on the stack - now execute the ‘inside‘. 178 goto case State.ResourceInside; 179 } 180 } 181 182 case State.ResourceAsyncBegin: 183 { 184 Debug.Assert(state != null); 185 Debug.Assert(_resourceExecutingContext != null); 186 187 var filter = (IAsyncResourceFilter)state; 188 var resourceExecutingContext = _resourceExecutingContext; 189 190 _diagnosticSource.BeforeOnResourceExecution(resourceExecutingContext, filter); 191 _logger.BeforeExecutingMethodOnFilter( 192 FilterTypeConstants.ResourceFilter, 193 nameof(IAsyncResourceFilter.OnResourceExecutionAsync), 194 filter); 195 196 var task = filter.OnResourceExecutionAsync(resourceExecutingContext, InvokeNextResourceFilterAwaitedAsync); 197 if (task.Status != TaskStatus.RanToCompletion) 198 { 199 next = State.ResourceAsyncEnd; 200 return task; 201 } 202 203 goto case State.ResourceAsyncEnd; 204 } 205 206 case State.ResourceAsyncEnd: 207 { 208 Debug.Assert(state != null); 209 Debug.Assert(_resourceExecutingContext != null); 210 211 var filter = (IAsyncResourceFilter)state; 212 if (_resourceExecutedContext == null) 213 { 214 // If we get here then the filter didn‘t call ‘next‘ indicating a short circuit. 215 _resourceExecutedContext = new ResourceExecutedContext(_resourceExecutingContext, _filters) 216 { 217 Canceled = true, 218 Result = _resourceExecutingContext.Result, 219 }; 220 221 _diagnosticSource.AfterOnResourceExecution(_resourceExecutedContext, filter); 222 _logger.AfterExecutingMethodOnFilter( 223 FilterTypeConstants.ResourceFilter, 224 nameof(IAsyncResourceFilter.OnResourceExecutionAsync), 225 filter); 226 227 // A filter could complete a Task without setting a result 228 if (_resourceExecutingContext.Result != null) 229 { 230 goto case State.ResourceShortCircuit; 231 } 232 } 233 234 goto case State.ResourceEnd; 235 } 236 237 case State.ResourceSyncBegin: 238 { 239 Debug.Assert(state != null); 240 Debug.Assert(_resourceExecutingContext != null); 241 242 var filter = (IResourceFilter)state; 243 var resourceExecutingContext = _resourceExecutingContext; 244 245 _diagnosticSource.BeforeOnResourceExecuting(resourceExecutingContext, filter); 246 _logger.BeforeExecutingMethodOnFilter( 247 FilterTypeConstants.ResourceFilter, 248 nameof(IResourceFilter.OnResourceExecuting), 249 filter); 250 251 filter.OnResourceExecuting(resourceExecutingContext); 252 253 _diagnosticSource.AfterOnResourceExecuting(resourceExecutingContext, filter); 254 _logger.AfterExecutingMethodOnFilter( 255 FilterTypeConstants.ResourceFilter, 256 nameof(IResourceFilter.OnResourceExecuting), 257 filter); 258 259 if (resourceExecutingContext.Result != null) 260 { 261 _resourceExecutedContext = new ResourceExecutedContext(resourceExecutingContext, _filters) 262 { 263 Canceled = true, 264 Result = _resourceExecutingContext.Result, 265 }; 266 267 goto case State.ResourceShortCircuit; 268 } 269 270 var task = InvokeNextResourceFilter(); 271 if (task.Status != TaskStatus.RanToCompletion) 272 { 273 next = State.ResourceSyncEnd; 274 return task; 275 } 276 277 goto case State.ResourceSyncEnd; 278 } 279 280 case State.ResourceSyncEnd: 281 { 282 Debug.Assert(state != null); 283 Debug.Assert(_resourceExecutingContext != null); 284 Debug.Assert(_resourceExecutedContext != null); 285 286 var filter = (IResourceFilter)state; 287 var resourceExecutedContext = _resourceExecutedContext; 288 289 _diagnosticSource.BeforeOnResourceExecuted(resourceExecutedContext, filter); 290 _logger.BeforeExecutingMethodOnFilter( 291 FilterTypeConstants.ResourceFilter, 292 nameof(IResourceFilter.OnResourceExecuted), 293 filter); 294 295 filter.OnResourceExecuted(resourceExecutedContext); 296 297 _diagnosticSource.AfterOnResourceExecuted(resourceExecutedContext, filter); 298 _logger.AfterExecutingMethodOnFilter( 299 FilterTypeConstants.ResourceFilter, 300 nameof(IResourceFilter.OnResourceExecuted), 301 filter); 302 303 goto case State.ResourceEnd; 304 } 305 306 case State.ResourceShortCircuit: 307 { 308 Debug.Assert(state != null); 309 Debug.Assert(_resourceExecutingContext != null); 310 Debug.Assert(_resourceExecutedContext != null); 311 312 _logger.ResourceFilterShortCircuited((IFilterMetadata)state); 313 314 _result = _resourceExecutingContext.Result; 315 var task = InvokeAlwaysRunResultFilters(); 316 if (task.Status != TaskStatus.RanToCompletion) 317 { 318 next = State.ResourceEnd; 319 return task; 320 } 321 322 goto case State.ResourceEnd; 323 } 324 325 case State.ResourceInside: 326 { 327 goto case State.ExceptionBegin; 328 } 329 330 case State.ExceptionBegin: 331 { 332 _cursor.Reset(); 333 goto case State.ExceptionNext; 334 } 335 336 case State.ExceptionNext: 337 { 338 var current = _cursor.GetNextFilter<IExceptionFilter, IAsyncExceptionFilter>(); 339 if (current.FilterAsync != null) 340 { 341 state = current.FilterAsync; 342 goto case State.ExceptionAsyncBegin; 343 } 344 else if (current.Filter != null) 345 { 346 state = current.Filter; 347 goto case State.ExceptionSyncBegin; 348 } 349 else if (scope == Scope.Exception) 350 { 351 // All exception filters are on the stack already - so execute the ‘inside‘. 352 goto case State.ExceptionInside; 353 } 354 else 355 { 356 // There are no exception filters - so jump right to the action. 357 Debug.Assert(scope == Scope.Invoker || scope == Scope.Resource); 358 goto case State.ActionBegin; 359 } 360 } 361 362 case State.ExceptionAsyncBegin: 363 { 364 var task = InvokeNextExceptionFilterAsync(); 365 if (task.Status != TaskStatus.RanToCompletion) 366 { 367 next = State.ExceptionAsyncResume; 368 return task; 369 } 370 371 goto case State.ExceptionAsyncResume; 372 } 373 374 case State.ExceptionAsyncResume: 375 { 376 Debug.Assert(state != null); 377 378 var filter = (IAsyncExceptionFilter)state; 379 var exceptionContext = _exceptionContext; 380 381 // When we get here we‘re ‘unwinding‘ the stack of exception filters. If we have an unhandled exception, 382 // we‘ll call the filter. Otherwise there‘s nothing to do. 383 if (exceptionContext?.Exception != null && !exceptionContext.ExceptionHandled) 384 { 385 _diagnosticSource.BeforeOnExceptionAsync(exceptionContext, filter); 386 _logger.BeforeExecutingMethodOnFilter( 387 FilterTypeConstants.ExceptionFilter, 388 nameof(IAsyncExceptionFilter.OnExceptionAsync), 389 filter); 390 391 var task = filter.OnExceptionAsync(exceptionContext); 392 if (task.Status != TaskStatus.RanToCompletion) 393 { 394 next = State.ExceptionAsyncEnd; 395 return task; 396 } 397 398 goto case State.ExceptionAsyncEnd; 399 } 400 401 goto case State.ExceptionEnd; 402 } 403 404 case State.ExceptionAsyncEnd: 405 { 406 Debug.Assert(state != null); 407 Debug.Assert(_exceptionContext != null); 408 409 var filter = (IAsyncExceptionFilter)state; 410 var exceptionContext = _exceptionContext; 411 412 _diagnosticSource.AfterOnExceptionAsync(exceptionContext, filter); 413 _logger.AfterExecutingMethodOnFilter( 414 FilterTypeConstants.ExceptionFilter, 415 nameof(IAsyncExceptionFilter.OnExceptionAsync), 416 filter); 417 418 if (exceptionContext.Exception == null || exceptionContext.ExceptionHandled) 419 { 420 // We don‘t need to do anything to trigger a short circuit. If there‘s another 421 // exception filter on the stack it will check the same set of conditions 422 // and then just skip itself. 423 _logger.ExceptionFilterShortCircuited(filter); 424 } 425 426 goto case State.ExceptionEnd; 427 } 428 429 case State.ExceptionSyncBegin: 430 { 431 var task = InvokeNextExceptionFilterAsync(); 432 if (task.Status != TaskStatus.RanToCompletion) 433 { 434 next = State.ExceptionSyncEnd; 435 return task; 436 } 437 438 goto case State.ExceptionSyncEnd; 439 } 440 441 case State.ExceptionSyncEnd: 442 { 443 Debug.Assert(state != null); 444 445 var filter = (IExceptionFilter)state; 446 var exceptionContext = _exceptionContext; 447 448 // When we get here we‘re ‘unwinding‘ the stack of exception filters. If we have an unhandled exception, 449 // we‘ll call the filter. Otherwise there‘s nothing to do. 450 if (exceptionContext?.Exception != null && !exceptionContext.ExceptionHandled) 451 { 452 _diagnosticSource.BeforeOnException(exceptionContext, filter); 453 _logger.BeforeExecutingMethodOnFilter( 454 FilterTypeConstants.ExceptionFilter, 455 nameof(IExceptionFilter.OnException), 456 filter); 457 458 filter.OnException(exceptionContext); 459 460 _diagnosticSource.AfterOnException(exceptionContext, filter); 461 _logger.AfterExecutingMethodOnFilter( 462 FilterTypeConstants.ExceptionFilter, 463 nameof(IExceptionFilter.OnException), 464 filter); 465 466 if (exceptionContext.Exception == null || exceptionContext.ExceptionHandled) 467 { 468 // We don‘t need to do anything to trigger a short circuit. If there‘s another 469 // exception filter on the stack it will check the same set of conditions 470 // and then just skip itself. 471 _logger.ExceptionFilterShortCircuited(filter); 472 } 473 } 474 475 goto case State.ExceptionEnd; 476 } 477 478 case State.ExceptionInside: 479 { 480 goto case State.ActionBegin; 481 } 482 483 case State.ExceptionHandled: 484 { 485 // We arrive in this state when an exception happened, but was handled by exception filters 486 // either by setting ExceptionHandled, or nulling out the Exception or setting a result 487 // on the ExceptionContext. 488 // 489 // We need to execute the result (if any) and then exit gracefully which unwinding Resource 490 // filters. 491 492 Debug.Assert(state != null); 493 Debug.Assert(_exceptionContext != null); 494 495 if (_exceptionContext.Result == null) 496 { 497 _exceptionContext.Result = new EmptyResult(); 498 } 499 500 _result = _exceptionContext.Result; 501 502 var task = InvokeAlwaysRunResultFilters(); 503 if (task.Status != TaskStatus.RanToCompletion) 504 { 505 next = State.ResourceInsideEnd; 506 return task; 507 } 508 509 goto case State.ResourceInsideEnd; 510 } 511 512 case State.ExceptionEnd: 513 { 514 var exceptionContext = _exceptionContext; 515 516 if (scope == Scope.Exception) 517 { 518 isCompleted = true; 519 return Task.CompletedTask; 520 } 521 522 if (exceptionContext != null) 523 { 524 if (exceptionContext.Result != null || 525 exceptionContext.Exception == null || 526 exceptionContext.ExceptionHandled) 527 { 528 goto case State.ExceptionHandled; 529 } 530 531 Rethrow(exceptionContext); 532 Debug.Fail("unreachable"); 533 } 534 535 var task = InvokeResultFilters(); 536 if (task.Status != TaskStatus.RanToCompletion) 537 { 538 next = State.ResourceInsideEnd; 539 return task; 540 } 541 goto case State.ResourceInsideEnd; 542 } 543 544 case State.ActionBegin: 545 { 546 var task = InvokeInnerFilterAsync(); 547 if (task.Status != TaskStatus.RanToCompletion) 548 { 549 next = State.ActionEnd; 550 return task; 551 } 552 553 goto case State.ActionEnd; 554 } 555 556 case State.ActionEnd: 557 { 558 if (scope == Scope.Exception) 559 { 560 // If we‘re inside an exception filter, let‘s allow those filters to ‘unwind‘ before 561 // the result. 562 isCompleted = true; 563 return Task.CompletedTask; 564 } 565 566 Debug.Assert(scope == Scope.Invoker || scope == Scope.Resource); 567 var task = InvokeResultFilters(); 568 if (task.Status != TaskStatus.RanToCompletion) 569 { 570 next = State.ResourceInsideEnd; 571 return task; 572 } 573 goto case State.ResourceInsideEnd; 574 } 575 576 case State.ResourceInsideEnd: 577 { 578 if (scope == Scope.Resource) 579 { 580 _resourceExecutedContext = new ResourceExecutedContext(_actionContext, _filters) 581 { 582 Result = _result, 583 }; 584 585 goto case State.ResourceEnd; 586 } 587 588 goto case State.InvokeEnd; 589 } 590 591 case State.ResourceEnd: 592 { 593 if (scope == Scope.Resource) 594 { 595 isCompleted = true; 596 return Task.CompletedTask; 597 } 598 599 Debug.Assert(scope == Scope.Invoker); 600 Rethrow(_resourceExecutedContext); 601 602 goto case State.InvokeEnd; 603 } 604 605 case State.InvokeEnd: 606 { 607 isCompleted = true; 608 return Task.CompletedTask; 609 } 610 611 default: 612 throw new InvalidOperationException(); 613 } 614 }
View Code
从代码可以看出,它是根据状态State进行轮转,而执行顺序是Authorization->Resource->Exception…… 也就是说当前action对应的多种类型的Filter会按照这样的顺序被执行,如下图
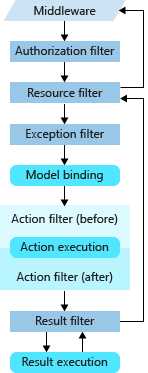
图四
可以看出,在上面几个Filter执行之后,ActionFilter的执行比较特殊,它将Action的执行包在了中间,这段逻辑写在了ControllerActionInvoker自己的类中,同样是一个 Task Next 方法被while循环调用,如下
1 private Task Next(ref State next, ref Scope scope, ref object state, ref bool isCompleted) 2 { 3 switch (next) 4 { 5 case State.ActionBegin: 6 { 7 var controllerContext = _controllerContext; 8 9 _cursor.Reset(); 10 11 _instance = _cacheEntry.ControllerFactory(controllerContext); 12 13 _arguments = new Dictionary<string, object>(StringComparer.OrdinalIgnoreCase); 14 15 var task = BindArgumentsAsync(); 16 if (task.Status != TaskStatus.RanToCompletion) 17 { 18 next = State.ActionNext; 19 return task; 20 } 21 22 goto case State.ActionNext; 23 } 24 25 case State.ActionNext: 26 { 27 var current = _cursor.GetNextFilter<IActionFilter, IAsyncActionFilter>(); 28 if (current.FilterAsync != null) 29 { 30 if (_actionExecutingContext == null) 31 { 32 _actionExecutingContext = new ActionExecutingContext(_controllerContext, _filters, _arguments, _instance); 33 } 34 35 state = current.FilterAsync; 36 goto case State.ActionAsyncBegin; 37 } 38 else if (current.Filter != null) 39 { 40 if (_actionExecutingContext == null) 41 { 42 _actionExecutingContext = new ActionExecutingContext(_controllerContext, _filters, _arguments, _instance); 43 } 44 45 state = current.Filter; 46 goto case State.ActionSyncBegin; 47 } 48 else 49 { 50 goto case State.ActionInside; 51 } 52 } 53 54 case State.ActionAsyncBegin: 55 { 56 Debug.Assert(state != null); 57 Debug.Assert(_actionExecutingContext != null); 58 59 var filter = (IAsyncActionFilter)state; 60 var actionExecutingContext = _actionExecutingContext; 61 62 _diagnosticSource.BeforeOnActionExecution(actionExecutingContext, filter); 63 _logger.BeforeExecutingMethodOnFilter( 64 MvcCoreLoggerExtensions.ActionFilter, 65 nameof(IAsyncActionFilter.OnActionExecutionAsync), 66 filter); 67 68 var task = filter.OnActionExecutionAsync(actionExecutingContext, InvokeNextActionFilterAwaitedAsync); 69 if (task.Status != TaskStatus.RanToCompletion) 70 { 71 next = State.ActionAsyncEnd; 72 return task; 73 } 74 75 goto case State.ActionAsyncEnd; 76 } 77 78 case State.ActionAsyncEnd: 79 { 80 Debug.Assert(state != null); 81 Debug.Assert(_actionExecutingContext != null); 82 83 var filter = (IAsyncActionFilter)state; 84 85 if (_actionExecutedContext == null) 86 { 87 // If we get here then the filter didn‘t call ‘next‘ indicating a short circuit. 88 _logger.ActionFilterShortCircuited(filter); 89 90 _actionExecutedContext = new ActionExecutedContext( 91 _controllerContext, 92 _filters, 93 _instance) 94 { 95 Canceled = true, 96 Result = _actionExecutingContext.Result, 97 }; 98 } 99 100 _diagnosticSource.AfterOnActionExecution(_actionExecutedContext, filter); 101 _logger.AfterExecutingMethodOnFilter( 102 MvcCoreLoggerExtensions.ActionFilter, 103 nameof(IAsyncActionFilter.OnActionExecutionAsync), 104 filter); 105 106 goto case State.ActionEnd; 107 } 108 109 case State.ActionSyncBegin: 110 { 111 Debug.Assert(state != null); 112 Debug.Assert(_actionExecutingContext != null); 113 114 var filter = (IActionFilter)state; 115 var actionExecutingContext = _actionExecutingContext; 116 117 _diagnosticSource.BeforeOnActionExecuting(actionExecutingContext, filter); 118 _logger.BeforeExecutingMethodOnFilter( 119 MvcCoreLoggerExtensions.ActionFilter, 120 nameof(IActionFilter.OnActionExecuting), 121 filter); 122 123 filter.OnActionExecuting(actionExecutingContext); 124 125 _diagnosticSource.AfterOnActionExecuting(actionExecutingContext, filter); 126 _logger.AfterExecutingMethodOnFilter( 127 MvcCoreLoggerExtensions.ActionFilter, 128 nameof(IActionFilter.OnActionExecuting), 129 filter); 130 131 if (actionExecutingContext.Result != null) 132 { 133 // Short-circuited by setting a result. 134 _logger.ActionFilterShortCircuited(filter); 135 136 _actionExecutedContext = new ActionExecutedContext( 137 _actionExecutingContext, 138 _filters, 139 _instance) 140 { 141 Canceled = true, 142 Result = _actionExecutingContext.Result, 143 }; 144 145 goto case State.ActionEnd; 146 } 147 148 var task = InvokeNextActionFilterAsync(); 149 if (task.Status != TaskStatus.RanToCompletion) 150 { 151 next = State.ActionSyncEnd; 152 return task; 153 } 154 155 goto case State.ActionSyncEnd; 156 } 157 158 case State.ActionSyncEnd: 159 { 160 Debug.Assert(state != null); 161 Debug.Assert(_actionExecutingContext != null); 162 Debug.Assert(_actionExecutedContext != null); 163 164 var filter = (IActionFilter)state; 165 var actionExecutedContext = _actionExecutedContext; 166 167 _diagnosticSource.BeforeOnActionExecuted(actionExecutedContext, filter); 168 _logger.BeforeExecutingMethodOnFilter( 169 MvcCoreLoggerExtensions.ActionFilter, 170 nameof(IActionFilter.OnActionExecuted), 171 filter); 172 173 filter.OnActionExecuted(actionExecutedContext); 174 175 _diagnosticSource.AfterOnActionExecuted(actionExecutedContext, filter); 176 _logger.AfterExecutingMethodOnFilter( 177 MvcCoreLoggerExtensions.ActionFilter, 178 nameof(IActionFilter.OnActionExecuted), 179 filter); 180 181 goto case State.ActionEnd; 182 } 183 184 case State.ActionInside: 185 { 186 var task = InvokeActionMethodAsync(); 187 if (task.Status != TaskStatus.RanToCompletion) 188 { 189 next = State.ActionEnd; 190 return task; 191 } 192 193 goto case State.ActionEnd; 194 } 195 196 case State.ActionEnd: 197 { 198 if (scope == Scope.Action) 199 { 200 if (_actionExecutedContext == null) 201 { 202 _actionExecutedContext = new ActionExecutedContext(_controllerContext, _filters, _instance) 203 { 204 Result = _result, 205 }; 206 } 207 208 isCompleted = true; 209 return Task.CompletedTask; 210 } 211 212 var actionExecutedContext = _actionExecutedContext; 213 Rethrow(actionExecutedContext); 214 215 if (actionExecutedContext != null) 216 { 217 _result = actionExecutedContext.Result; 218 } 219 220 isCompleted = true; 221 return Task.CompletedTask; 222 } 223 224 default: 225 throw new InvalidOperationException(); 226 } 227 }
View Code
而在ActionBegin的时候,通过ControllerFactory创建了Controller并调用 cacheEntry.ControllerBinderDelegate(_controllerContext, _instance, _arguments) 进行了参数绑定。
然后的顺序是 ActionFilter的OnActionExecuting方法 ->action的执行->ActionFilter的OnActionExecuted方法, action的执行如下:
private async Task InvokeActionMethodAsync() { var controllerContext = _controllerContext; var objectMethodExecutor = _cacheEntry.ObjectMethodExecutor; var controller = _instance; var arguments = _arguments; var actionMethodExecutor = _cacheEntry.ActionMethodExecutor; var orderedArguments = PrepareArguments(arguments, objectMethodExecutor); var diagnosticSource = _diagnosticSource; var logger = _logger; IActionResult result = null; try { diagnosticSource.BeforeActionMethod( controllerContext, arguments, controller); logger.ActionMethodExecuting(controllerContext, orderedArguments); var stopwatch = ValueStopwatch.StartNew(); var actionResultValueTask = actionMethodExecutor.Execute(_mapper, objectMethodExecutor, controller, orderedArguments); if (actionResultValueTask.IsCompletedSuccessfully) { result = actionResultValueTask.Result; } else { result = await actionResultValueTask; } _result = result; logger.ActionMethodExecuted(controllerContext, result, stopwatch.GetElapsedTime()); } finally { diagnosticSource.AfterActionMethod( controllerContext, arguments, controllerContext, result); } }
总结: 如上文说的,本节的内容就是将准备阶段组装的多个方法在这里按一定的被逐步的执行(如图四)。
大概内容就是这样,详细分析起来涉及细节还有好多,后面的文章会对一些关键内容进行详细分享。