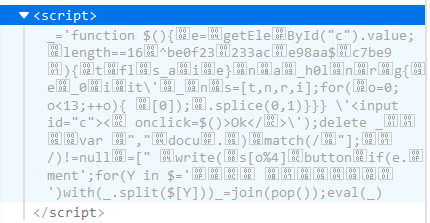
查看源码之后
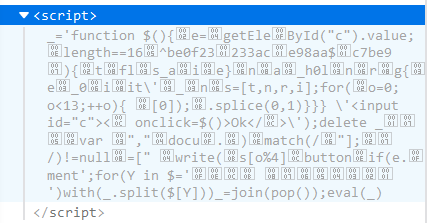
带着script标签一同保存到本地里,保存为后缀名为html的文件,并把里面的eval改为alert,让他可以弹出来,打开文件

啊哦,出来了,整理一下
function $(){
var e=document.getElementById("c").value;
if(e.length==16)
if(e.match(/^be0f23/)!=null)
if(e.match(/233ac/)!=null)
if(e.match(/e98aa$/)!=null)
if(e.match(/c7be9/)!=null){
var t=["fl","s_a","i","e}"];
var n=["a","_h0l","n"];
var r=["g{","e","_0"];
var i=["it‘","_","n"];
var s=[t,n,r,i];
for(var o=0;o<13;++o){
document.write(s[o%4][0]);s[o%4].splice(0,1)
}
}
}
document.write(‘<input id="c"><button onclick=$()>Ok</button>‘);
delete
不用根据这些个变量和document.write去算flag,拿到flag有两种方法:
1)满足正则
首先,满足length==16,正则的话^为开始符号,$为结尾符号,拼接一下:be0f233ac7be98aa,输入就拿到flag了。
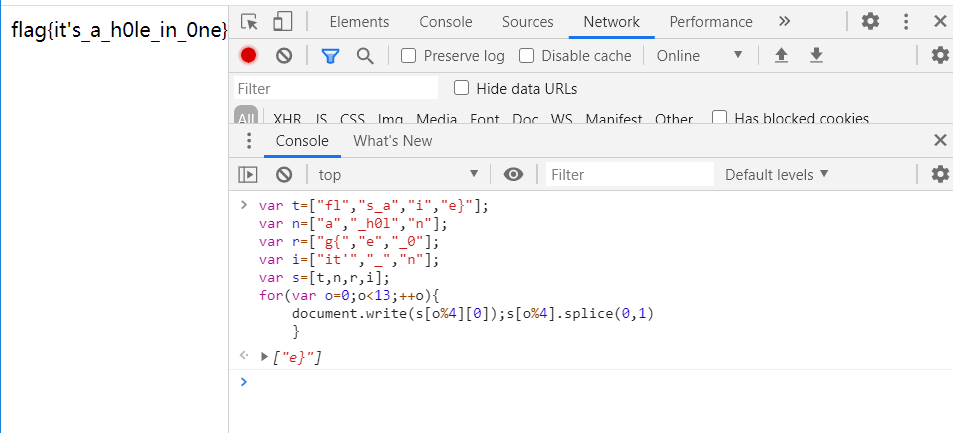
2)将下面这段拿到控制台执行一下即可:
var t=["fl","s_a","i","e}"];
var n=["a","_h0l","n"];
var r=["g{","e","_0"];
var i=["it‘","_","n"];
var s=[t,n,r,i];
for(var o=0;o<13;++o){
document.write(s[o%4][0]);s[o%4].splice(0,1)
}
}
flag{it‘s_a_h0le_in_0ne}