HTML 5中的DataList控件元素有助于提供自动完成功能的文本框,如下图所示。
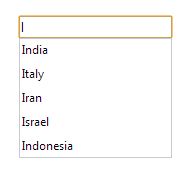
下面是DataList控件功能的HTML代码:
<input list="Country">
<datalist id="Country">
<option value="India">
<option value="Italy">
<option value="Iran">
<option value="Israel">
<option value="Indonesia">
</datalist>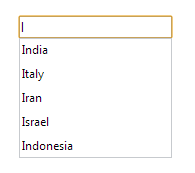
HTML 5中的DataList控件元素有助于提供自动完成功能的文本框,如下图所示。
下面是DataList控件功能的HTML代码:
<input list="Country">
<datalist id="Country">
<option value="India">
<option value="Italy">
<option value="Iran">
<option value="Israel">
<option value="Indonesia">
</datalist>