CVE-2019-0232:Apache Tomcat RCE复现
0X00漏洞简介
该漏洞是由于Tomcat CGI将命令行参数传递给Windows程序的方式存在错误,使得CGIServlet被命令注入影响。
该漏洞只影响Windows平台,要求启用了CGIServlet和enableCmdLineArguments参数。但是CGIServlet和enableCmdLineArguments参数默认情况下都不启用。
漏洞影响范围: Apache Tomcat 9.0.0.M1 to 9.0.17
Apache Tomcat 8.5.0 to 8.5.39
Apache Tomcat 7.0.0 to 7.0.93
0X01漏洞环境搭建
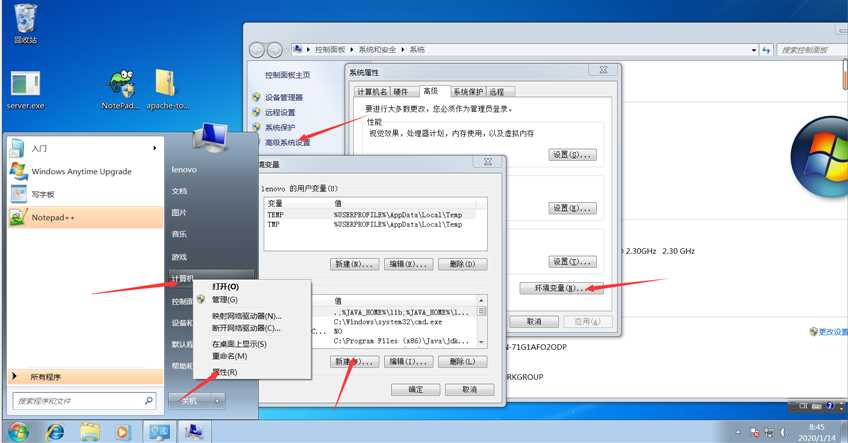
1.进行变量配置:
首先下载jdk文件安装,成功后开始变量配置。
以win7为例开始→我的电脑→右键属性→高级系统设置→环境变量→系统变量→新建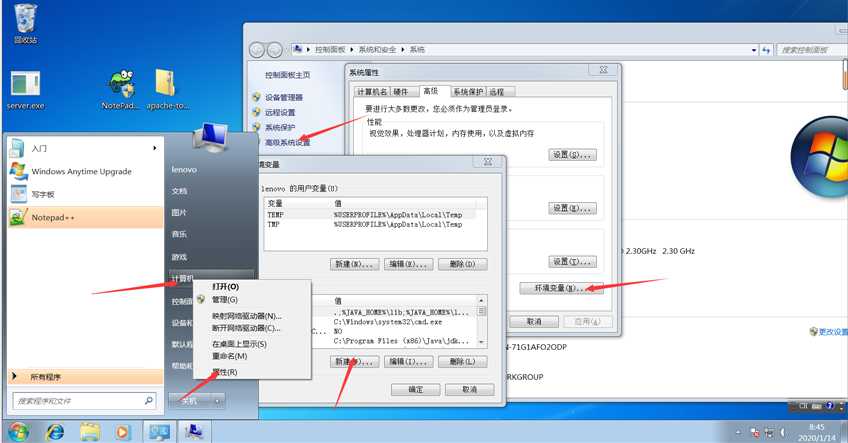
新建变量名为JAVA_HOME的变量变量值为你安装jdk的路径
例:变量名:JAVA_HOME变量值:C:\Program Files (x86)\Java\jdk1.8.0_73
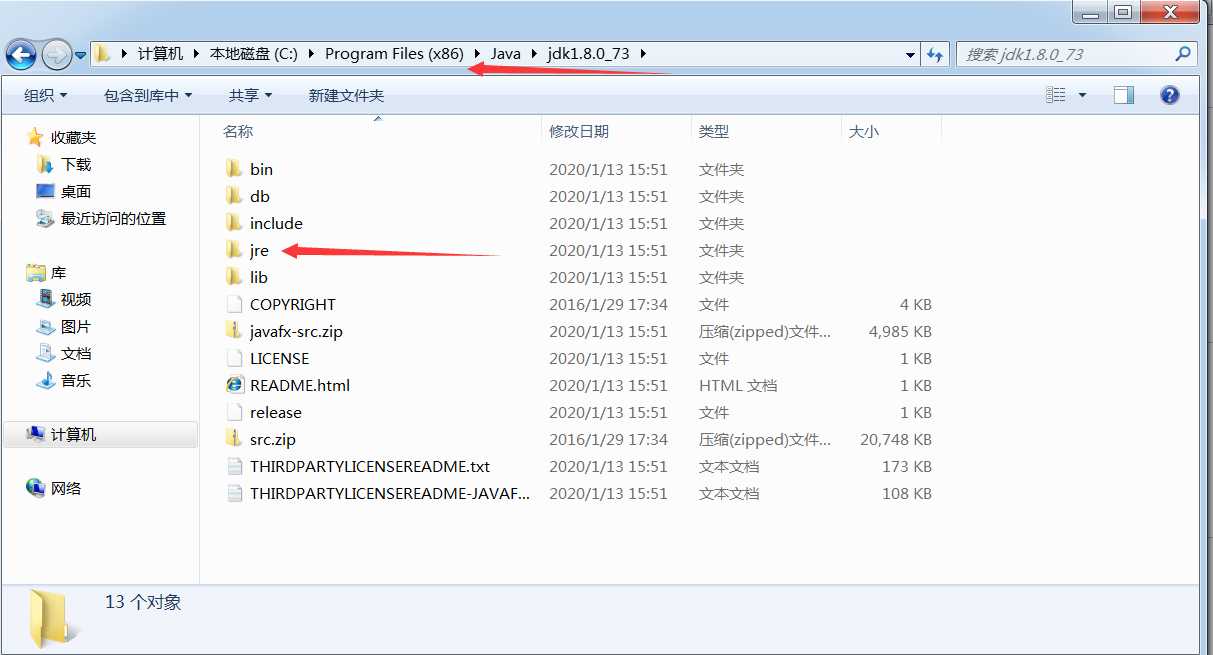
新建变量名为JRE_HOME的变量变量值为你安装jdk文件夹中jre文件夹的路径
例:变量名JRE_HOME变量值: C:\Program Files (x86)\Java\jdk1.8.0_73\jre
新建变量名为CLASSPATH的变量变量值为.;%JAVA_HOME%\lib;%JAVA_HOME%\lib\tools.jar(ps:前面有个点)
在变量path新增变量值为;%JAVA_HOME%\bin;%JAVA_HOME%\jre\bin(ps:前面有;)
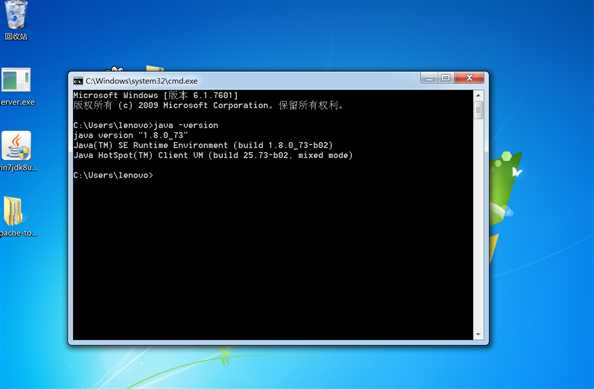
配好变量后打开cmd命令框输入java –version出现java版本号等信息则说明变量安装成功。
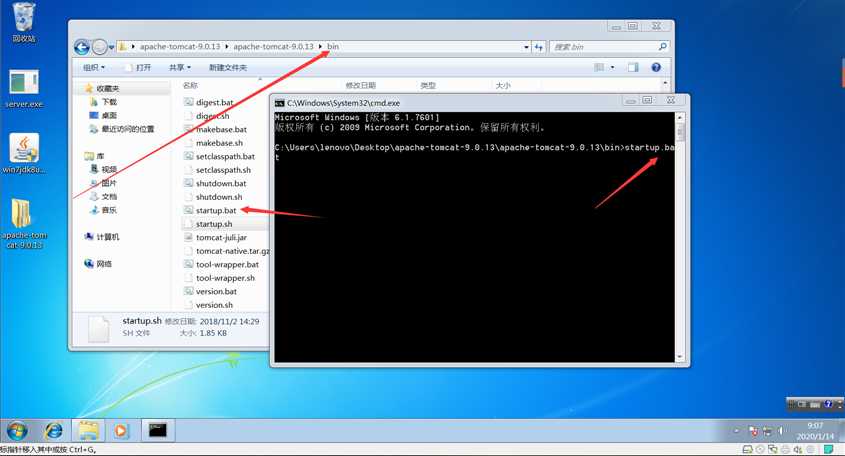
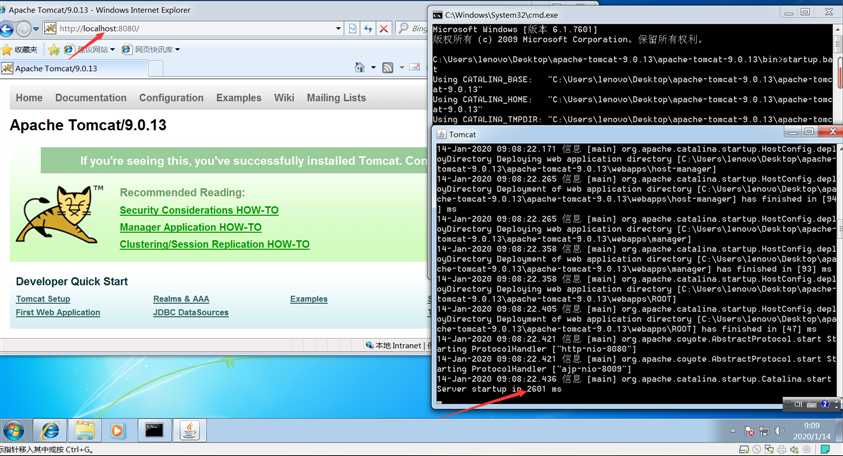
2.将你的tomcat文件解压到你要安装的文件夹,进入文件夹中的bin文件夹,使用cmd命令执行startup.bat文件,出现加载界面,待加载完成后在浏览器访问http://localhost:8080界面访问成功则说明tomcat安装成功。
https://archive.apache.org/dist/tomcat/ 该链接为tomcat各个版本下载链接
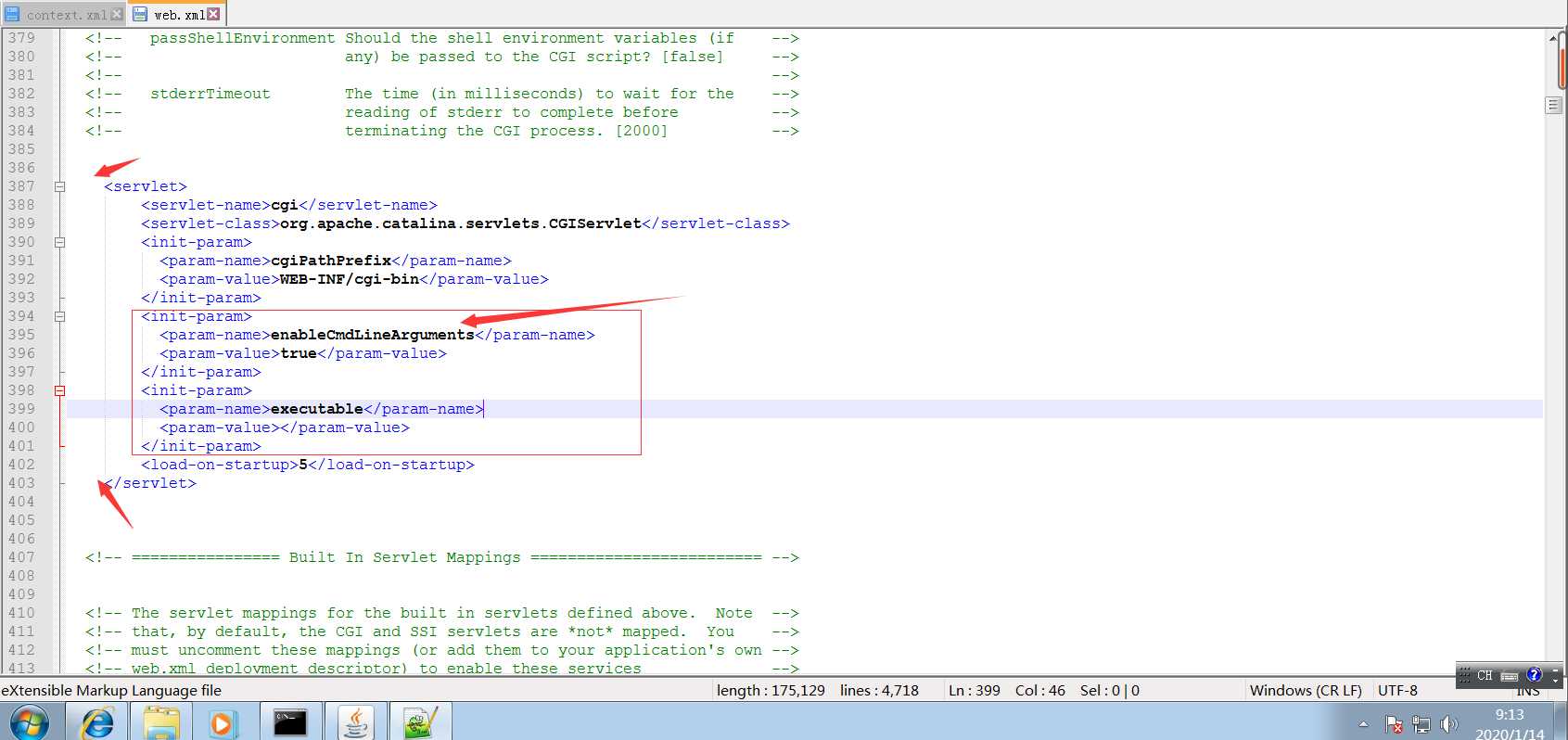
3.修改配置文件
Tomcat的CGI_Servlet组件默认是关闭的,在 conf/web.xml 中找到注释的CGIServlet部分,去掉注释,并配置enableCmdLineArguments和executable(需要取消掉注释的一共是俩部分)
(ps:下方红框内的内容需要手打,原文件本来没有这个参数,9.0版本默认关闭)
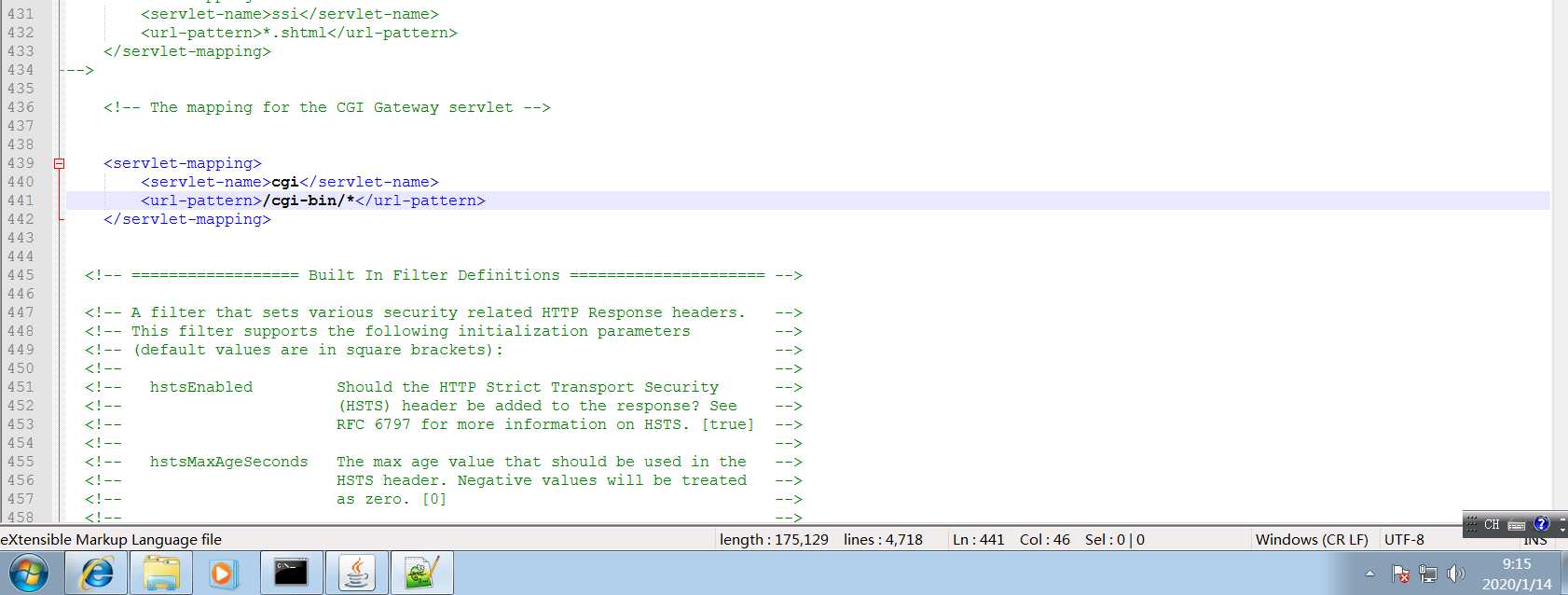
接着修改conf/context.xml中的<Context>添加privileged=”true”语句

然后在C:\Users\lenovo\Desktop\apache-tomcat-9.0.13\apache-tomcat-9.0.13
\webapps\ROOT\WEB-INF下创建一个cgi-bin文件夹,并在文件夹内创建一个bat文件可以什么都不写或者写一些bat语句。
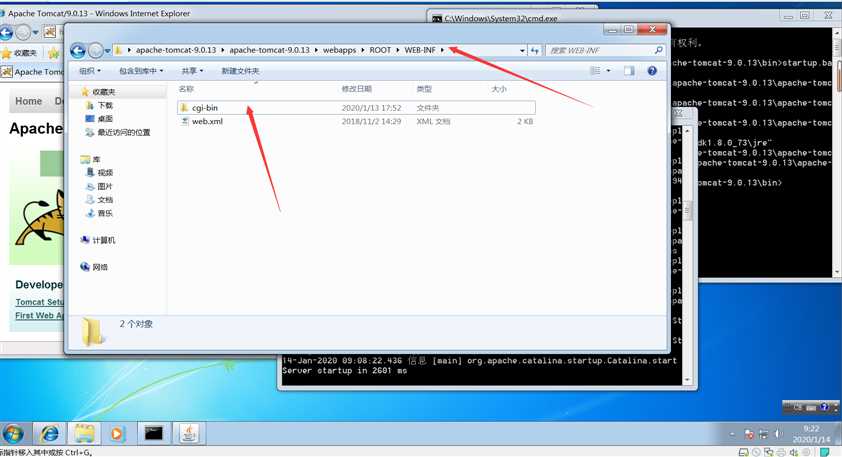
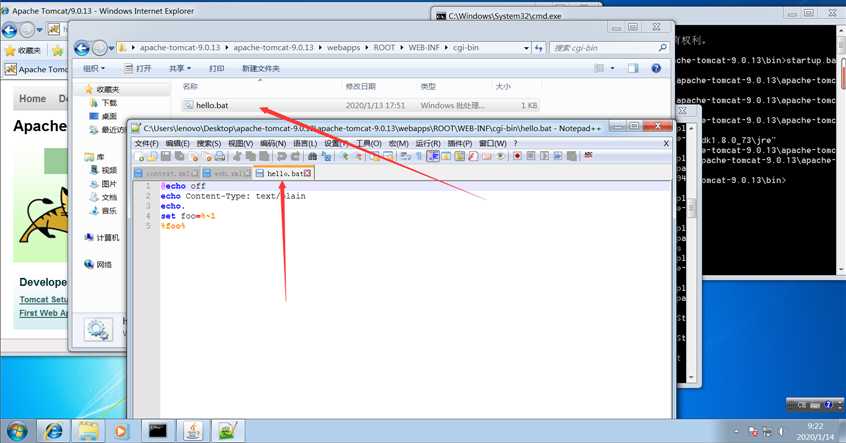
到此所有的环境准备完成。
4.重启tomcat服务(确保配置生效)
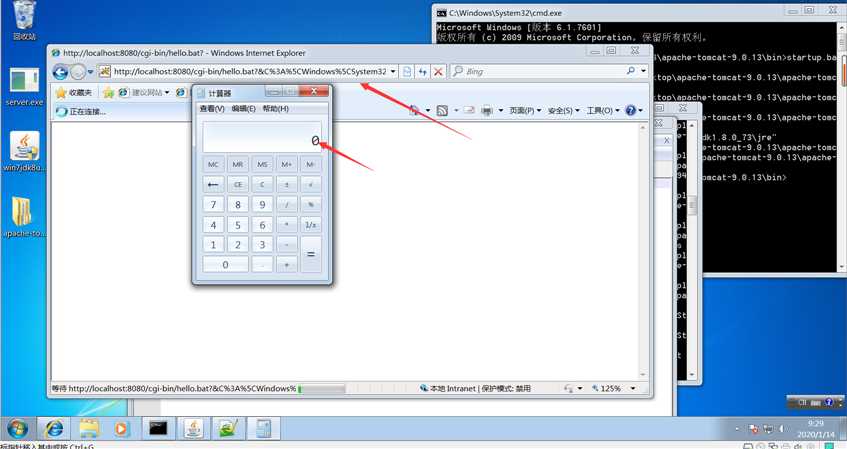
5.利用payload为:
http://localhost:8080/cgi-bin/hello.bat?&C%3A%5CWindows%5CSystem32%5Ccalc.exe
该payload为打开计算器
访问之后成功打开计算器
0X02漏洞原理
漏洞相关的代码在 tomcat\java\org\apache\catalina\servlets\CGIServlet.java 中,CGIServlet提供了一个cgi的调用接口,在启用 enableCmdLineArguments 参数时,会根据RFC 3875来从Url参数中生成命令行参数,并把参数传递至Java的 Runtime 执行。 这个漏洞是因为 Runtime.getRuntime().exec 在Windows中和Linux中底层实现不同导致的。
但是在tomcat9.0.13中已经严格限制了有效字符
0X03漏洞修复
因为在9.版本以上CGIServlet和enableCmdLineArguments参数默认情况下都不启用
所以影响不是很大。
开发者在URLDecoder.decode解码后增加一个正则表达式验证,毋庸置疑,目的肯定是检测url解码后的字符串输入的合法性。
因此最有效的修复方式是:
- 禁用enableCmdLineArguments参数。
- 在conf/web.xml中覆写采用更严格的参数合法性检验规则。
- 升级tomcat到9.0.17以上版本。