Skip to content
California, TX 70240 | (1800) 456 7890
云博客
云博客
前端
windos
微信
数据库
移动开发
技术杂谈
前端
windos
微信
数据库
移动开发
技术杂谈
Home
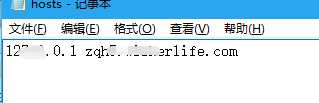
关于微信本地修改可以时时测试,本地ip映射域名问题
38efbb5f73fd73a8d5b52c27ed80f768.jpg
38efbb5f73fd73a8d5b52c27ed80f768.jpg
发表回复
要发表评论,您必须先
登录
。